Moving
- 02 Aug 2019As a brief update, with more to follow, I’ll be relocating to Florida in order to better help my father with his health issues. Excited for this new phase!
Epidemics
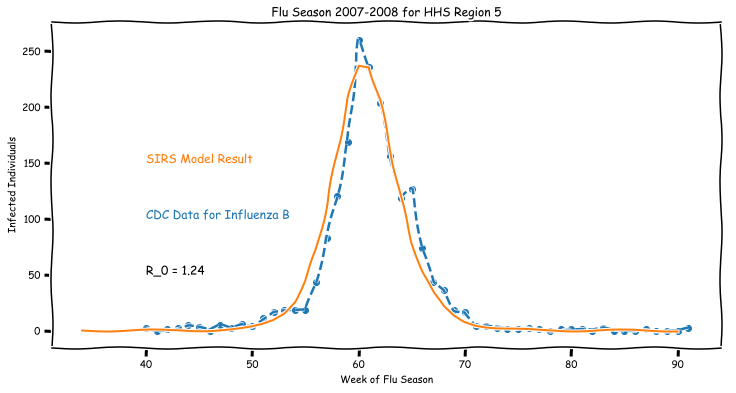
- 04 Jan 2019The SIR model is an example of a compartmental model used to simplify the mathematical modeling the spread of infectious diseases. While the SIR model gets a lot of attention for its use as a toy model for testing implementations, or demonstrating the power of ODEs for modeling nonlinear systems, it’s a surprisingly good fit for actual data.
Govlov Podcast
- 07 Sep 2018My recent work on data-driven rural sociology was featured today on the GovLov Podcast. Thanks to Ben Kittelson for taking the time to talk with us!
Reboot
- 24 Aug 2018I decided the site needed a drastic reboot, tore down the old bootstrap page, and decided to try out Jekyll.